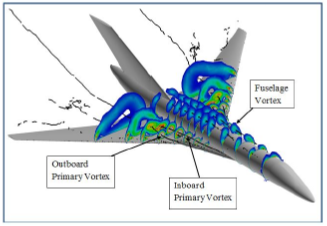
The vertical flow over the TCR (transonic cruiser configuration).
Computational Fluid Dynamics(CFD) simulations are anticipated to become the primary tool in the design of modern commercial and military aircraft. Specifically, CFD has become reliable enough to detect the source of undesirable flight characteristics experienced in the flight testing. However, CFD techniques are subject to inaccuracies and must be validated and evaluated on the basis of experimental data. Researchers at the US Air Force Academy have been using Cobalt to predict static and forced motion aerodynamic responses of a canard configured TransCRuiser named the TCR. In the process, they have also examined and validated the use of Cobalt’s Overset method to simulate canard deflections.Continue reading